目标检测
- 目标识别图片里的多个物体的类比和位置
- 位置通常用边缘框表示
数据集
不同于图像分类的数据集,一个子文件夹一个分类
- 每行表示一个物体
- 图片文件名,物体类别,边缘框
- COCO
- 80物体,330K图片,1.5M物体
边缘框(bbox)
-
一个边缘框可以通过4个数字定义
- (左上x,左上y,
右上x,右下y)
- (左上x,左上y,
宽, 高)
def box_corner_to_center(boxes):
"""从(左上,右下)转换到(中间,宽度,高度)"""
x1, y1, x2, y2 = boxes[:, 0], boxes[:, 1], boxes[:, 2], boxes[:, 3]
cx = (x1 + x2) / 2
cy = (y1 + y2) / 2
w = x2 - x1
h = y2 - y1
boxes = torch.stack((cx, cy, w, h), axis=-1)
return boxes
def box_center_to_corner(boxes):
"""从(中间,宽度,高度)转换到(左上,右下)"""
cx, cy, w, h = boxes[:, 0], boxes[:, 1], boxes[:, 2], boxes[:, 3]
x1 = cx - 0.5 * w
y1 = cy - 0.5 * h
x2 = cx + 0.5 * w
y2 = cy + 0.5 * h
boxes = torch.stack((x1, y1, x2, y2), axis=-1)
return boxes锚框(anchor box)
- 一类目标检测算法是基于锚框
- 提出多个被称为锚框的区域(边缘框)
- 预测每个锚框里是否含有关注的物体
- 如果是,预测从这个锚框到真实边缘框的偏移
IoU 交并比
-
Intersection over Union
-
IoU用于计算两个框之间的相似度
- 0表示无重叠,1表示重合
-
计算两个框的相似度(雅可比指数的特殊情况)
- 先计算两个框的交集
- 再计算两个框的并集
- 交集于并集的比率就是IoU
def box_iou(boxes1, boxes2):
"""计算两个锚框或边界框列表中成对的交并比"""
box_area = lambda boxes: ((boxes[:, 2] - boxes[:, 0]) *
(boxes[:, 3] - boxes[:, 1]))
# boxes1,boxes2,areas1,areas2的形状:
# boxes1:(boxes1的数量,4),
# boxes2:(boxes2的数量,4),
# areas1:(boxes1的数量,),
# areas2:(boxes2的数量,)
areas1 = box_area(boxes1)
areas2 = box_area(boxes2)
# inter_upperlefts,inter_lowerrights,inters的形状:
# (boxes1的数量,boxes2的数量,2)
inter_upperlefts = torch.max(boxes1[:, None, :2], boxes2[:, :2])
inter_lowerrights = torch.min(boxes1[:, None, 2:], boxes2[:, 2:])
inters = (inter_lowerrights - inter_upperlefts).clamp(min=0)
# inter_areasandunion_areas的形状:(boxes1的数量,boxes2的数量)
inter_areas = inters[:, :, 0] * inters[:, :, 1]
union_areas = areas1[:, None] + areas2 - inter_areas
return inter_areas / union_areas生成锚框
- 锚框的宽度和高度分别是
ws√r和hs/√r- 即只考虑组合:(s1,r1), (s1,r2), ... , (s1,rm), (s2,r1), (s3, r1), ... , (sn,r1)
- 第一个size和所有的ratio组合,其余的size和第一个ratio组合
- 以每个像素为中心生成不同形状的锚框
- 每个像素生成的锚框个数为:len(size) + len(ratio) - 1
- 一个图片生成的锚框个数为:wh*(len(size) + len(ratio) - 1)
def multibox_prior(data, sizes, ratios):
"""生成以每个像素为中心具有不同形状的锚框"""
in_height, in_width = data.shape[-2:]
device, num_sizes, num_ratios = data.device, len(sizes), len(ratios)
boxes_per_pixel = (num_sizes + num_ratios - 1)
size_tensor = torch.tensor(sizes, device=device)
ratio_tensor = torch.tensor(ratios, device=device)
# 为了将锚点移动到像素的中心,需要设置偏移量。
# 因为一个像素的的高为1且宽为1,我们选择偏移我们的中心0.5
offset_h, offset_w = 0.5, 0.5
steps_h = 1.0 / in_height # 在y轴上缩放步长
steps_w = 1.0 / in_width # 在x轴上缩放步长
# 生成锚框的所有中心点
center_h = (torch.arange(in_height, device=device) + offset_h) * steps_h
center_w = (torch.arange(in_width, device=device) + offset_w) * steps_w
shift_y, shift_x = torch.meshgrid(center_h, center_w)
shift_y, shift_x = shift_y.reshape(-1), shift_x.reshape(-1)
# 生成“boxes_per_pixel”个高和宽,
# 之后用于创建锚框的四角坐标(xmin,xmax,ymin,ymax)
w = torch.cat((size_tensor * torch.sqrt(ratio_tensor[0]),
sizes[0] * torch.sqrt(ratio_tensor[1:])))\
* in_height / in_width # 处理矩形输入
h = torch.cat((size_tensor / torch.sqrt(ratio_tensor[0]),
sizes[0] / torch.sqrt(ratio_tensor[1:])))
# 除以2来获得半高和半宽
anchor_manipulations = torch.stack((-w, -h, w, h)).T.repeat(
in_height * in_width, 1) / 2
# 每个中心点都将有“boxes_per_pixel”个锚框,
# 所以生成含所有锚框中心的网格,重复了“boxes_per_pixel”次
out_grid = torch.stack([shift_x, shift_y, shift_x, shift_y],
dim=1).repeat_interleave(boxes_per_pixel, dim=0)
output = out_grid + anchor_manipulations
return output.unsqueeze(0)赋予锚框标号
- 每个锚框是一个训练样本
- 将每个锚框,要么标注成背景,要么关联上一个真实的边缘框
- 目标检测算法会生成大量的锚框
- 会产生大量的负样本
真实边框分配给锚框
def assign_anchor_to_bbox(ground_truth, anchors, device, iou_threshold=0.5):
"""将最接近的真实边界框分配给锚框"""
num_anchors, num_gt_boxes = anchors.shape[0], ground_truth.shape[0]
# 位于第i行和第j列的元素x_ij是锚框i和真实边界框j的IoU
jaccard = box_iou(anchors, ground_truth)
# 对于每个锚框,分配的真实边界框的张量
anchors_bbox_map = torch.full((num_anchors,), -1, dtype=torch.long,
device=device)
# 根据阈值,决定是否分配真实边界框
max_ious, indices = torch.max(jaccard, dim=1)
anc_i = torch.nonzero(max_ious >= 0.5).reshape(-1)
box_j = indices[max_ious >= 0.5]
anchors_bbox_map[anc_i] = box_j
col_discard = torch.full((num_anchors,), -1)
row_discard = torch.full((num_gt_boxes,), -1)
for _ in range(num_gt_boxes):
max_idx = torch.argmax(jaccard)
box_idx = (max_idx % num_gt_boxes).long()
anc_idx = (max_idx / num_gt_boxes).long()
anchors_bbox_map[anc_idx] = box_idx
jaccard[:, box_idx] = col_discard
jaccard[anc_idx, :] = row_discard
return anchors_bbox_map锚框与真实边框的偏移量
def offset_boxes(anchors, assigned_bb, eps=1e-6):
"""对锚框偏移量的转换"""
c_anc = d2l.box_corner_to_center(anchors)
c_assigned_bb = d2l.box_corner_to_center(assigned_bb)
offset_xy = 10 * (c_assigned_bb[:, :2] - c_anc[:, :2]) / c_anc[:, 2:]
offset_wh = 5 * torch.log(eps + c_assigned_bb[:, 2:] / c_anc[:, 2:])
offset = torch.cat([offset_xy, offset_wh], axis=1)
return offset标记多个锚框的分类、偏移量
def multibox_target(anchors, labels):
"""使用真实边界框标记锚框"""
batch_size, anchors = labels.shape[0], anchors.squeeze(0)
batch_offset, batch_mask, batch_class_labels = [], [], []
device, num_anchors = anchors.device, anchors.shape[0]
for i in range(batch_size):
label = labels[i, :, :]
anchors_bbox_map = assign_anchor_to_bbox(
label[:, 1:], anchors, device)
bbox_mask = ((anchors_bbox_map >= 0).float().unsqueeze(-1)).repeat(
1, 4)
# 将类标签和分配的边界框坐标初始化为零
class_labels = torch.zeros(num_anchors, dtype=torch.long,
device=device)
assigned_bb = torch.zeros((num_anchors, 4), dtype=torch.float32,
device=device)
# 使用真实边界框来标记锚框的类别。
# 如果一个锚框没有被分配,我们标记其为背景(值为零)
indices_true = torch.nonzero(anchors_bbox_map >= 0)
bb_idx = anchors_bbox_map[indices_true]
class_labels[indices_true] = label[bb_idx, 0].long() + 1
assigned_bb[indices_true] = label[bb_idx, 1:]
# 偏移量转换
offset = offset_boxes(anchors, assigned_bb) * bbox_mask
batch_offset.append(offset.reshape(-1))
batch_mask.append(bbox_mask.reshape(-1))
batch_class_labels.append(class_labels)
bbox_offset = torch.stack(batch_offset)
bbox_mask = torch.stack(batch_mask)
class_labels = torch.stack(batch_class_labels)
return (bbox_offset, bbox_mask, class_labels)非极大值抑制(NMS)预测边界框
-
Non-Maximum Suppression
-
每个锚框预测一个边缘框
-
NMS可以合并相似的预测
- 选中是非背景类的最大预测值
- 去掉所有其它和它IoU值大于Θ(阈值 )的预测值
- 重复上述过程直到所有预测要么被选中,要么被去掉
-
NMS两种常用做法:
- 1.对所有类的锚框放到一起做NMS
- 2.对每一个类的锚框做NMS
偏移量转回坐标
def offset_inverse(anchors, offset_preds):
"""根据带有预测偏移量的锚框来预测边界框"""
anc = d2l.box_corner_to_center(anchors)
pred_bbox_xy = (offset_preds[:, :2] * anc[:, 2:] / 10) + anc[:, :2]
pred_bbox_wh = torch.exp(offset_preds[:, 2:] / 5) * anc[:, 2:]
pred_bbox = torch.cat((pred_bbox_xy, pred_bbox_wh), axis=1)
predicted_bbox = d2l.box_center_to_corner(pred_bbox)
return predicted_bbox非极大值抑制
def nms(boxes, scores, iou_threshold):
"""对预测边界框的置信度进行排序"""
B = torch.argsort(scores, dim=-1, descending=True)
keep = [] # 保留预测边界框的指标
while B.numel() > 0:
i = B[0]
keep.append(i)
if B.numel() == 1: break
iou = box_iou(boxes[i, :].reshape(-1, 4),
boxes[B[1:], :].reshape(-1, 4)).reshape(-1)
inds = torch.nonzero(iou <= iou_threshold).reshape(-1)
B = B[inds + 1]
return torch.tensor(keep, device=boxes.device)调用NMS预测边界框
def multibox_detection(cls_probs, offset_preds, anchors, nms_threshold=0.5,
pos_threshold=0.009999999):
"""使用非极大值抑制来预测边界框"""
device, batch_size = cls_probs.device, cls_probs.shape[0]
anchors = anchors.squeeze(0)
num_classes, num_anchors = cls_probs.shape[1], cls_probs.shape[2]
out = []
for i in range(batch_size):
cls_prob, offset_pred = cls_probs[i], offset_preds[i].reshape(-1, 4)
conf, class_id = torch.max(cls_prob[1:], 0)
predicted_bb = offset_inverse(anchors, offset_pred)
keep = nms(predicted_bb, conf, nms_threshold)
# 找到所有的non_keep索引,并将类设置为背景
all_idx = torch.arange(num_anchors, dtype=torch.long, device=device)
combined = torch.cat((keep, all_idx))
uniques, counts = combined.unique(return_counts=True)
non_keep = uniques[counts == 1]
all_id_sorted = torch.cat((keep, non_keep))
class_id[non_keep] = -1
class_id = class_id[all_id_sorted]
conf, predicted_bb = conf[all_id_sorted], predicted_bb[all_id_sorted]
# pos_threshold是一个用于非背景预测的阈值
below_min_idx = (conf < pos_threshold)
class_id[below_min_idx] = -1
conf[below_min_idx] = 1 - conf[below_min_idx]
pred_info = torch.cat((class_id.unsqueeze(1),
conf.unsqueeze(1),
predicted_bb), dim=1)
out.append(pred_info)
return torch.stack(out)R-CNN
- 使用启发式搜索算法来选择锚框
- 使用预训练模型来对每个锚框抽取特征
- 训练一个SVM来对类别分类
- 训练一个线性回归模型来预测边缘框偏移
小结
- 尽管 R-CNN 模型通过预训练的卷积神经网络有效地抽取了图像特征,但是速度非常慢(如果从一张图片中选取了上千个提议区域,就需要上千次的卷积神经网络的前向传播来执行目标检测,计算量非常大)
Fast RCNN
- 使用CNN对图片抽取特征
- 使用ROI池化层对每个锚框生成固定长度的特征
- Fast R-CNN 的改进是:在拿到一张图片之后,首先使用 CNN 对图片进行特征提取(不是对图片中的锚框进行特征提取,而是对整张图片进行特征提取,仅在整张图像上执行卷积神经网络的前向传播),最终会得到一个 7 7 或者 14 14 的 feature map
- 抽取完特征之后,再对图片进行锚框的选择(selective search),搜索到原始图片上的锚框之后将其(按照一定的比例)映射到 CNN 的输出上
- 映射完锚框之后,再使用 RoI pooling 对 CNN 输出的 feature map 上的锚框进行特征抽取,生成固定长度的特征(将 n * m 的矩阵拉伸成为 nm 维的向量),之后再通过一个全连接层(这样就不需要使用SVM一个一个的操作,而是一次性操作了)对每个锚框进行预测:物体的类别和真实的边缘框的偏移
- 上图中黄色方框的作用就是将原图中生成的锚框变成对应的向量
- Fast R-CNN 相对于 R-CNN 更快的原因是:Fast R-CNN 中的 CNN 不再对每个锚框抽取特征,而是对整个图片进行特征的提取(这样做的好处是:不同的锚框之间可能会有重叠的部分,如果对每个锚框都进行特征提取的话,可能会对重叠的区域进行多次重复的特征提取操作),然后再在整张图片的feature中找出原图中锚框对应的特征,最后一起做预测
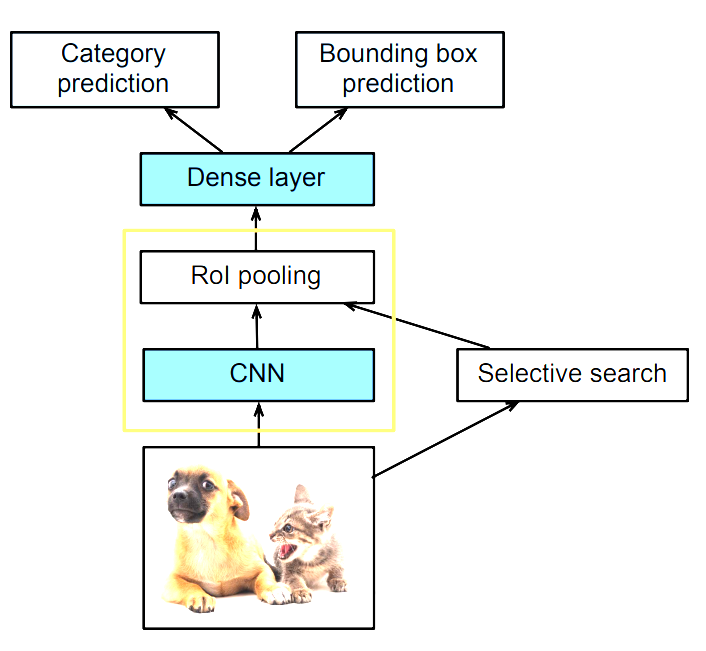
兴趣区域(ROI)池化层
-
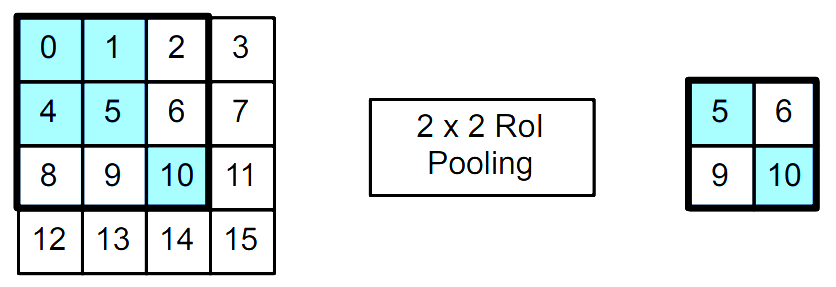
R-CNN 中比较关键的层,作用是将大小不一的锚框变成统一的形状
-
给定一个锚框,均匀分割成nxm块,输出每块里的最大值
-
不管锚框多大,总是输出nm个值
-
于是不同大小的锚框总是可以处理成同样的大小,然后作为一个小批量进行前向计算抽取特征
-
与普通的池化层的区别?
- 在一般的汇聚层中,通过设置汇聚窗口、填充和步幅的大小来间接控制输出形状
- 在兴趣区域汇聚层中,对每个区域的输出形状是可以直接指定的
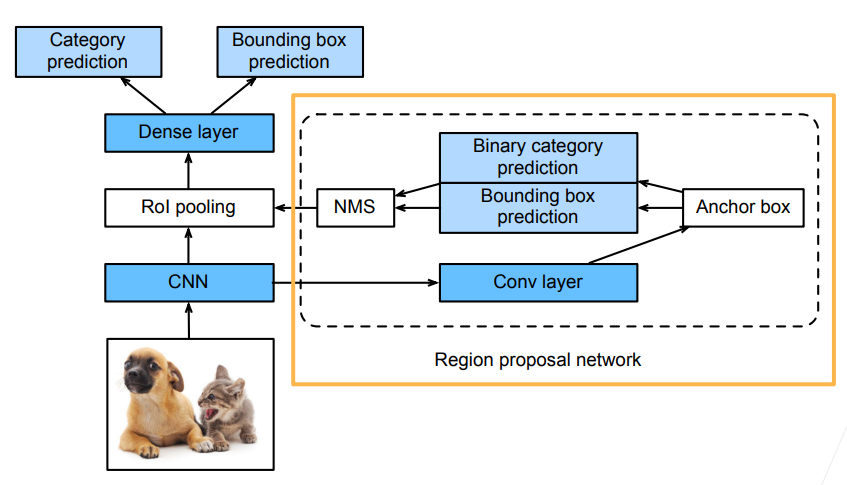
Faster RCNN
- 为了精确地检测目标结果,Fast R-CNN 模型通常需要在选择性搜索中生成大量的提议区域
- 因此,Faster R-CNN 提出将选择性搜索替换为区域提议网络(region proposal network,RPN),模型的其余部分保持不变,从而减少区域的生成数量,并保证目标检测的精度
- RoI 的输入是CNN 输出的 feature map 和生成的锚框
- RPN 的输入是 CNN 输出的 feature map,输出是一些比较高质量的锚框(可以理解为一个比较小而且比较粗糙的目标检测算法: CNN 的输出进入到 RPN 之后再做一次卷积,然后生成一些锚框(可以是 selective search 或者其他方法来生成初始的锚框),再训练一个二分类问题:预测锚框是否框住了真实的物体以及锚框到真实的边缘框的偏移,最后使用 NMS 进行去重,使得锚框的数量变少)
- RPN 的作用是生成大量结果很差的锚框,然后进行预测,最终输出比较好的锚框供后面的网络使用(预测出来的比较好的锚框会进入 RoI pooling,后面的操作与 Fast R-CNN 类似)
- 通常被称为两阶段的目标检测算法:RPN 做小的目标检测(粗糙),整个网络再做一次大的目标检测(精准)
- Faster R-CNN 目前来说是用的比较多的算法,准确率比较高,但是速度比较慢
Mask RCNN
- 如果在训练集中还标注了每个目标在图像上的像素级位置,Mask R-CNN 能够有效地利用这些相近地标注信息进一步提升目标检测地精度
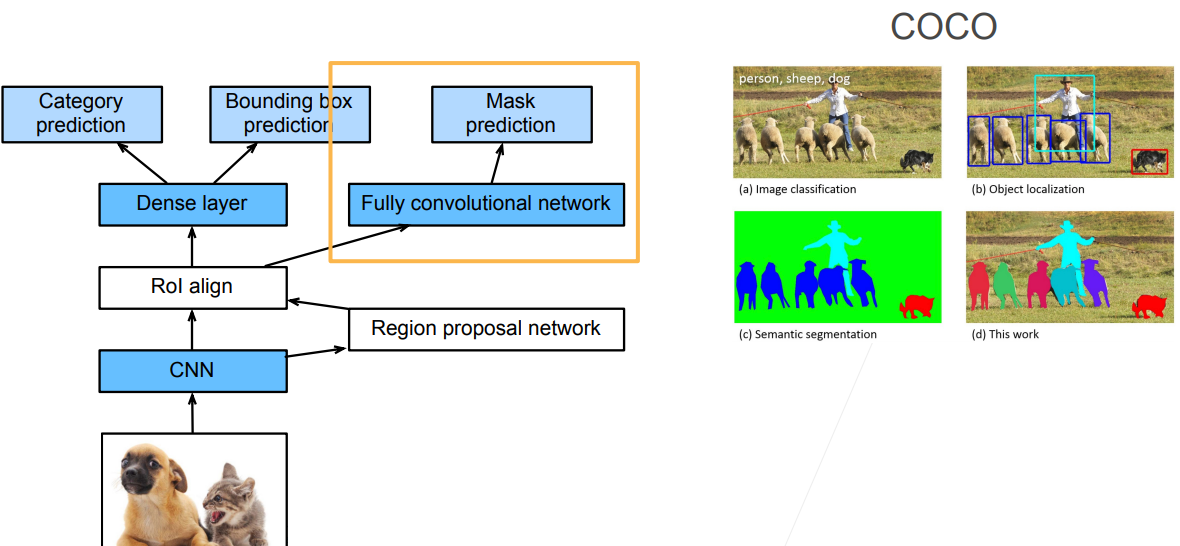
Mask R-CNN 是基于 Faster R-CNN 修改而来的,改进在于
- 假设有每个像素的标号的话,就可以对每个像素做预测(FCN)
- 将兴趣区域汇聚层替换成了兴趣区域对齐层(RoI pooling -> RoI align),使用双线性插值(bilinear interpolation)保留特征图上的空间信息,进而更适于像素级预测:对于pooling来说,假如有一个3 3的区域,需要对它进行2 2的RoI pooling操作,那么会进行取整从而切割成为不均匀的四个部分,然后进行 pooling 操作,这样切割成为不均匀的四部分的做法对于目标检测来说没有太大的问题,因为目标检测不是像素级别的,偏移几个像素对结果没有太大的影响。但是对于像素级别的标号来说,会产生极大的误差;RoI align 不管能不能整除,如果不能整除的话,会直接将像素切开,切开后的每一部分是原像素的加权(它的值是原像素的一部分)
- 兴趣区域对齐层的输出包含了所有与兴趣区域的形状相同的特征图,它们不仅被用于预测每个兴趣区域的类别和边界框,还通过额外的全卷积网络预测目标的像素级位置
RCNN家族小结
- R-CNN 是最早、也是最有名的一类基于锚框和 CNN 的目标检测算法(R-CNN 可以认为是使用神经网络来做目标检测工作的奠基工作之一),它对图像选取若干提议区域,使用卷积神经网络对每个提议区域执行前向传播以抽取其特征,然后再用这些特征来预测提议区域的类别和边框
- Fast/Faster R-CNN持续提升性能:Fast R-CNN 只对整个图像做卷积神经网络的前向传播,还引入了兴趣区域汇聚层(RoI pooling),从而为具有不同形状的兴趣区域抽取相同形状的特征;Faster R-CNN 将 Fast R-CNN 中使用的选择性搜索替换为参与训练的区域提议网络,这样可以在减少提议区域数量的情况下仍然保持目标检测的精度;Mask R-CNN 在 Faster R-CNN 的基础上引入了一个全卷积网络,从而借助目标的像素级位置进一步提升目标检测的精度
- Faster R-CNN 和 Mask R-CNN 是在追求高精度场景下的常用算法(Mask R-CNN 需要有像素级别的标号,所以相对来讲局限性会大一点,在无人车领域使用的比较多)
SSD
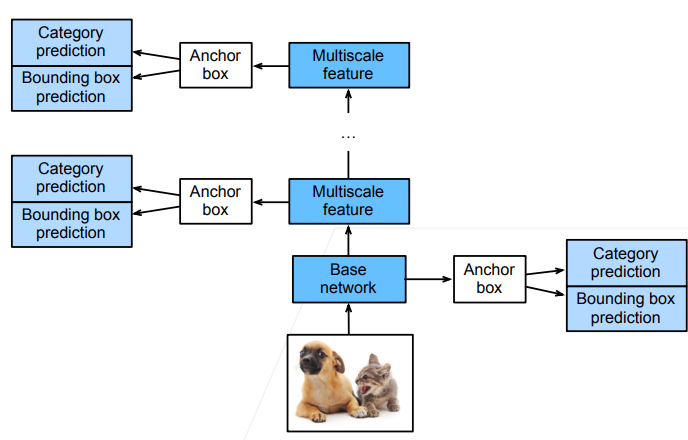
- 输入图像之后,首先进入一个基础网络来抽取特征,抽取完特征之后对每个像素生成大量的锚框(每个锚框就是一个样本,然后预测锚框的类别以及到真实边界框的偏移)
- SSD 在给定锚框之后直接对锚框进行预测,而不需要做两阶段(为什么 Faster RCNN 需要做两次,而 SSD 只需要做一次?SSD 通过做不同分辨率下的预测来提升最终的效果,越到底层的 feature map,就越大,越往上,feature map 越少,因此底层更加有利于小物体的检测,而上层更有利于大物体的检测)
- SSD 不再使用 RPN 网络,而是直接在生成的大量样本(锚框)上做预测,看是否包含目标物体;如果包含目标物体,再预测该样本到真实边缘框的偏移
小结
- SSD通过单神经网络来检测模型
- 以每个像素为中心产生多个锚框
- 在多个段的输出上进行多尺度的检测(底层检测小物体,上层检测大物体)
YOLO
- you only look once
- yolo 也是一个 single-stage 的算法,只有一个单神经网络来做预测
- yolo 也需要锚框,这点和 SSD 相同,但是 SSD 是对每个像素点生成多个锚框,所以在绝大部分情况下两个相邻像素的所生成的锚框的重叠率是相当高的,这样就会导致很大的重复计算量。
- yolo 的想法是尽量让锚框不重叠:首先将图片均匀地分成 S S 块,每一块就是一个锚框,每一个锚框预测 B 个边缘框(考虑到一个锚框中可能包含多个物体),所以最终就会产生 S ^ 2 B 个样本,因此速度会远远快于 SSD
- yolo 在后续的版本(V2,V3,V4...)中有持续的改进,但是核心思想没有变,真实的边缘框不会随机的出现,真实的边缘框的比例、大小在每个数据集上的出现是有一定的规律的,在知道有一定的规律的时候就可以使用聚类算法将这个规律找出来(给定一个数据集,先分析数据集中的统计信息,然后找出边缘框出现的规律,这样之后在生成锚框的时候就会有先验知识,从而进一步做出优化)