记录一次GPU集群的存储崩溃
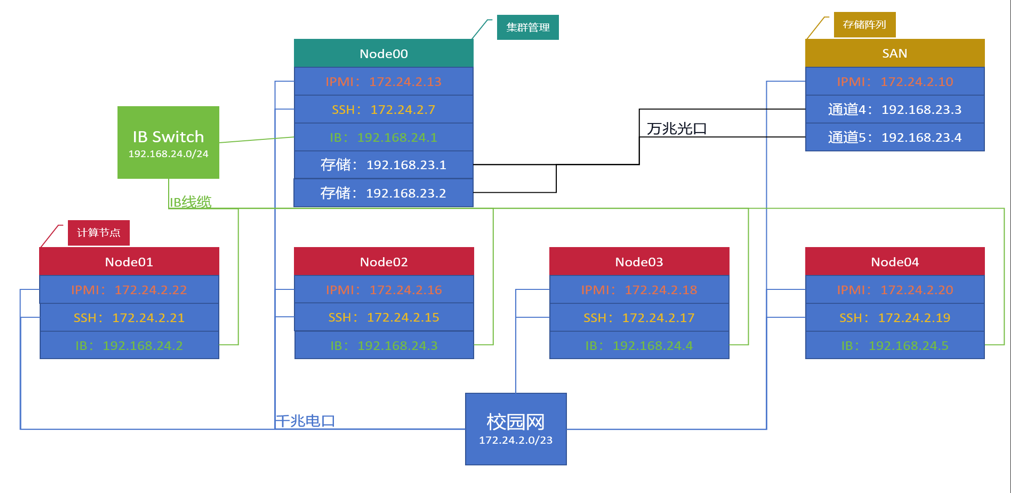
集群架构:整个GPU集群由4台GPU服务器、一台CPU服务器、一个存储阵列(大概200T)组成。存储阵列是通过一个万兆交换机连接到这个Node00管理节点。其它计算设备都是走的管理节点的映射。
前两天新到一台服务器,准备并入这个集群里面。 供应商需要安装一个软件进行交付,结果导致所有SAN磁盘的I/O出现的问题。
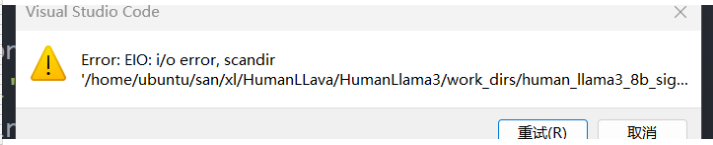
因为供应商不靠谱,然后我们开始排查。最后定位到是因为管理节点的重启,而进行计算的若干节点并没有停止导致数据不一致性。这点也是经常出现在分布式系统里面的情况,而对于磁盘来说,也不用回退检查点,因为本身存储就做了备份冗余。所以解决方案就是
解除所有绑定到Node00的计算节点。
1 如果遇到device is busy 就kill对应进程,直到能够解绑
shell sudo fuser-m-k/home/ubuntu/san/在管理节点运行使用fsck对文件系统进行扫描修复
重启绑定
这样就完成了存储崩溃的处理